In today’s world, where companies have to deal with huge amounts of data, the issue of data management efficiency becomes more and more important. One of the solutions to optimize data management and improve performance is to use Virtual Schemas in Exasol, a high-performance in-memory database.
In the following, we present a performance test of Exasol Virtual Schema to reduce the amount of data in an Exasol cluster environment. The idea behind this technique is to use a smaller Exasol cluster with a storage (memory) license and offload data to it.
Offloading data to a smaller cluster can lead to better performance by reducing the amount of active data that needs to be stored on the main Exasol instance. It also allows for greater flexibility by not having to keep the data on the main cluster all the time, resulting in better use of resources.
To perform this test, we use the Virtual Schema Adapter, which is written in Java. This adapter allows us to interact with Exasol via JDBC.
First we create the schema and the adapter:
CREATE SCHEMA X_SCHEMA_FOR_VS_SCRIPT;
CREATE OR REPLACE JAVA ADAPTER SCRIPT X_SCHEMA_FOR_VS_SCRIPT.ADAPTER_SCRIPT_EXASOL AS
%scriptclass com.exasol.adapter.RequestDispatcher;
%jar /buckets/bfsdefault/vschema/virtual-schema-dist-10.5.0-exasol-7.1.1.jar;
/
We then define two connections to our Exasol instance, one JDBC and one native Exasol connection:
CREATE OR REPLACE CONNECTION JDBC_CONNECTION_EXA_DEV1
TO 'jdbc:exa:1.112.32.331..333/FINGERPRINT:8565'
USER 'SYS'
IDENTIFIED BY 'xx';
CREATE OR REPLACE CONNECTION EXA_CONNECTION_DEV1
TO '1.112.32.331..333/FINGERPRINT:8565'
USER 'SYS'
IDENTIFIED BY 'xx';
After that we create the Virtual Schema with the JDBC connection we created earlier:
After that, the data will be merged with the data from the other source:
Since we do not want that another query is necessary than before. It should remain transparent for our customer!
create or replace view FULL_DATA
as select * from ACTUAL_DATA
where datadate > sysdate-interval '1' MONTH
union all
select * from VIRTUAL_EXASOL_DEV1.ARCHIVE_DATA
where datadate < sysdate- interval '1' MONTH;
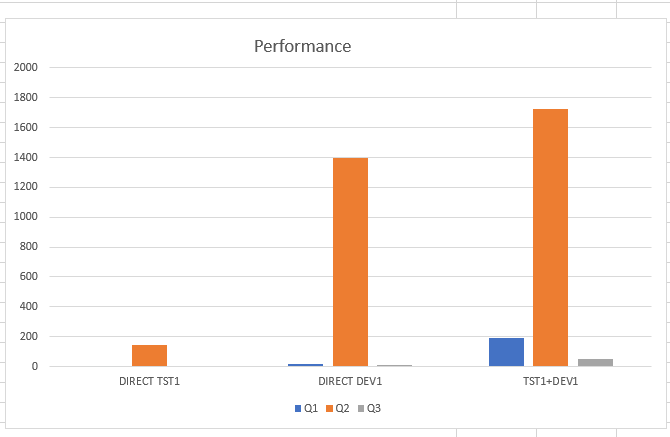
When we do a performance test we see that there is a clear difference if we do a query on a large database or on 2 databases when they are linked via Union All and Virtual Schema.
DEV1 is really slow – but cheap!
The optimizer of course passes the Where Clause, but still fetches all the necessary data over the network. And that takes time. Note: Runtime in seconds.
Conclusion: Depending on the query, the query performance has an effect. If you only need a few data for a calculation, it is of course not so dramatic, but we achieved a slowness factor between 11 upto 157 in our tests. Since we only tested with simple queries, this is still an important knowhow for us.
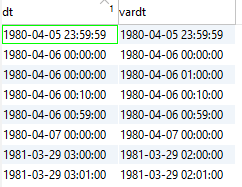
Customer reports that the time does not arrive correctly from SQL Server to Exasol – basically Daylight Saving Times
SPHINX.AT
He even sends a test case that can be reproduced 1 to 1.
Here is a small excerpt from the preparation:
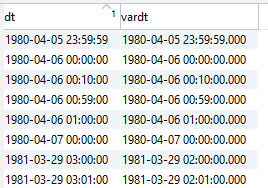
Sql Server: (Create view for testing)
create view datetimetest as
select dt,convert(varchar,dt, 21) as vardt
from (
select try_convert(DATETIME,'1980-04-05 23:59:59.000',102) as dt
union all
select try_convert(DATETIME,'1980-04-06 00:00:00.000',102) as dt
union all
select try_convert(DATETIME,'1980-04-06 00:10:00.000',102) as dt
union all
select try_convert(DATETIME,'1980-04-06 00:59:00.000',102) as dt
union all
select try_convert(DATETIME,'1980-04-06 01:00:00.000',102) as dt
union all
select try_convert(DATETIME,'1980-04-07 00:00:00.000',102) as dt
union all
select try_convert(DATETIME,'1981-03-29 02:00:00.000',102) as dt
union all
select try_convert(DATETIME,'1981-03-29 02:01:00.000',102) as dt
) a;
Exasol: (Query the data via Exasol)
SELECT *
FROM ( IMPORT FROM jdbc at con_mssql STATEMENT
'select * from dbo.datetimetest')
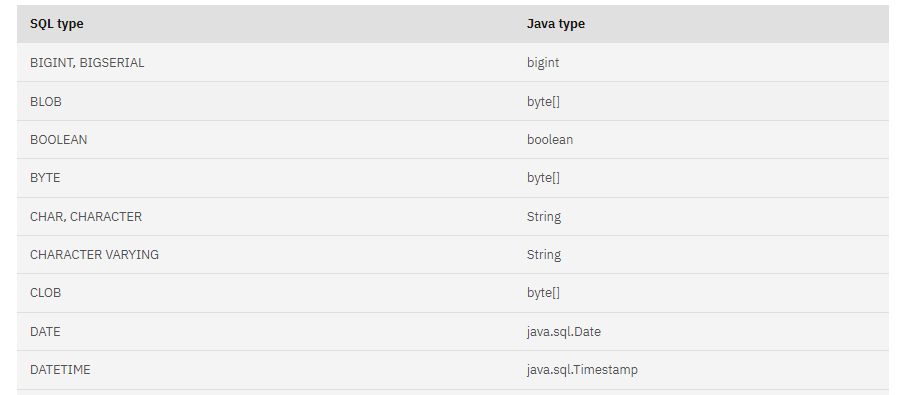
Why can a date actually become a timestamp? Data type of SQL Server becomes Timestamp in jdbc driver. => Because it converts Java/JDBC!
SQL datatyp to Java Type
Which setting must now be set how, so that we take over the DATETIME(2) correctly? It is actually only converted if it does not correspond to the default UTC.
And in ExaOperation we see (not easy to find) the answer: in Extra Database Parameters the user.timezone is set to Europe/Vienna?!
„The exact String is: -etlJdbcJavaEnv=-Duser.timezone=Europe/Vienna“
You barely change this setting and reboot the machine:
USE UTC !
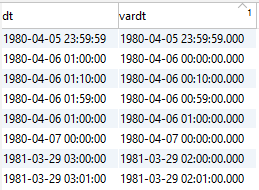
Lo and behold Exasol query now returns the same result as SQL Server:
YES!
Problem solved?
unfortunately NOT – THE PROBLEM IS NOW AT POSTGRES ! IN CASE OF TIMESTAMP WITH TIME ZONE!
After further analysis we found out that due to a bug with Postgres this setting was set to Europe/Vienna. (from 2020)
Now we have to find out if this bug still exists…
In fact there was or is a bug with Postgres datatype timestamp with TIME ZONE… and lo and behold… the bug is still there almost 3 years later.
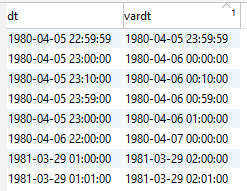
Postgres: (create testview in Postgres SQL)
create or replace view datetimetest as
select dt dtwotz, dt at time zone 'Europe/Vienna' as dt,cast(dt as text) as vardt
from (
select
cast('1980-04-05 23:59:59.000' as timestamp without time zone) as dt
union all
select
cast('1980-04-06 00:00:00.000' as timestamp without time zone) as dt
union all
select
cast('1980-04-06 00:10:00.000' as timestamp without time zone) as dt
union all
select
cast('1980-04-06 00:59:00.000' as timestamp without time zone) as dt
union all
select
cast('1980-04-06 01:00:00.000' as timestamp without time zone) as dt
union all
select
cast('1980-04-07 00:00:00.000' as timestamp without time zone) as dt
union all
select
cast('1981-03-29 02:00:00.000' as timestamp without time zone) as dt
union all
select
cast('1981-03-29 02:01:00.000' as timestamp without time zone) as dt
) a;
Posgres Query Result
Now still using user.timezone = UTC from Exasol to query on Postgres:
OMG – in EXASOL -1 and -2 diffs?
If we switch back to Europe/Vienna we have the problem with SQL Server.
Therefore we have to decide:
Postgres vs. SQL Server => which system is more important 🙂
Urge Exasol to fix the bug, it is open since 2020.
implement workaround => load it into varchar and then convert it into timestamp with TZ (for SQL Server or for Postgres is basically the same)
Exasol and Oracle are both powerful relational database management systems that can be used for different use cases.
SPHINX.AT
Below are what I consider to be the top 5 features of Exasol compared to an Oracle database:
Exasol’s shared-nothing architecture means that each node in the cluster has its own resources such as CPU, RAM and disk space and operates independently of other nodes. This ensures high scalability and resilience, since if a node fails, only its data is affected and not the entire system.
In addition, Exasol provides automatic data distribution and replication to minimize data access time and increase availability. In-memory technology ensures that typically 10-15% of the data is quickly available in memory, while the rest is offloaded to disk. The high level of parallelization and scalability makes it possible to process large amounts of data in a short time, making Exasol a popular solution for data analysis and business intelligence.
Scalability: Exasol can scale horizontally and vertically and thus offers high scalability. Oracle, on the other hand, is not as easy to scale and usually requires more effort.
Easy administration: The administration of Exasol databases is easier than the administration of Oracle databases. Since there is simply not that much to manage 😉 We don’t need to configure and monitor RAC or Data Guard.
Real-time processing: Exasol can process data in real time, enabling real-time analysis and decision making. Oracle also offers this feature, but not at the same speed and efficiency as Exasol.
e.g.: If during the execution of a query it is determined that a certain execution plan is not optimal, the optimizer can generate a new plan and use it to process the query faster and more efficiently. (Adaptive Plan at Oracle)
Another example of dynamic optimization is adaptive indexing. Here the optimizer can decide which indexes are needed to make a query more efficient and create or remove these indexes at runtime. And that is really ingenious!
No light without shadow, but this is also communicated fairly and transparently by Exasol, this database is not suitable for an OLTP system. (SQL parsing and single inserts/updates are much slower than with an Oracle for example). There is also no point-in-time recovery, because there are no archive logs and therefore the last backup and its time are decisive which data can be recovered. And this is hard to argue for a normal OLTP application if this data was lost.
For me as a DBA an Exasol is a dream and as a developer by the integration of Python and R and other Languages anyway incredible.
As an Oracle developer I miss features like the Oracle Scheduler , Oracle VPD and of course the low code tool like Oracle Apex. However, it is possible to combine these two worlds to get the best out of it for our customers.
I also find Oracle PL/SQL more convenient than Exasol LUA. But I would prefer everything to run in Python only 😉