
In today’s world, where companies have to deal with huge amounts of data, the issue of data management efficiency becomes more and more important. One of the solutions to optimize data management and improve performance is to use Virtual Schemas in Exasol, a high-performance in-memory database.
In the following, we present a performance test of Exasol Virtual Schema to reduce the amount of data in an Exasol cluster environment. The idea behind this technique is to use a smaller Exasol cluster with a storage (memory) license and offload data to it.
Offloading data to a smaller cluster can lead to better performance by reducing the amount of active data that needs to be stored on the main Exasol instance. It also allows for greater flexibility by not having to keep the data on the main cluster all the time, resulting in better use of resources.
To perform this test, we use the Virtual Schema Adapter, which is written in Java. This adapter allows us to interact with Exasol via JDBC.
First we create the schema and the adapter:
CREATE SCHEMA X_SCHEMA_FOR_VS_SCRIPT;CREATE OR REPLACE JAVA ADAPTER SCRIPT X_SCHEMA_FOR_VS_SCRIPT.ADAPTER_SCRIPT_EXASOL AS
%scriptclass com.exasol.adapter.RequestDispatcher;
%jar /buckets/bfsdefault/vschema/virtual-schema-dist-10.5.0-exasol-7.1.1.jar;
/We then define two connections to our Exasol instance, one JDBC and one native Exasol connection:
CREATE OR REPLACE CONNECTION JDBC_CONNECTION_EXA_DEV1
TO 'jdbc:exa:1.112.32.331..333/FINGERPRINT:8565'
USER 'SYS'
IDENTIFIED BY 'xx';CREATE OR REPLACE CONNECTION EXA_CONNECTION_DEV1
TO '1.112.32.331..333/FINGERPRINT:8565'
USER 'SYS'
IDENTIFIED BY 'xx';After that we create the Virtual Schema with the JDBC connection we created earlier:
CREATE VIRTUAL SCHEMA VIRTUAL_EXASOL_DEV1
USING X_SCHEMA_FOR_VS_SCRIPT.ADAPTER_SCRIPT_EXASOL WITH
CONNECTION_NAME = 'JDBC_CONNECTION_EXA_DEV1'
SCHEMA_NAME = 'HISTORY_ARCHIVE'
IMPORT_FROM_EXA = 'true'
EXA_CONNECTION = 'EXA_CONNECTION_DEV1'
MAX_TABLE_COUNT = '10000';After that, the data will be merged with the data from the other source:
Since we do not want that another query is necessary than before. It should remain transparent for our customer!
create or replace view FULL_DATA
as select * from ACTUAL_DATA
where datadate > sysdate-interval '1' MONTH
union all
select * from VIRTUAL_EXASOL_DEV1.ARCHIVE_DATA
where datadate < sysdate- interval '1' MONTH;When we do a performance test we see that there is a clear difference if we do a query on a large database or on 2 databases when they are linked via Union All and Virtual Schema.
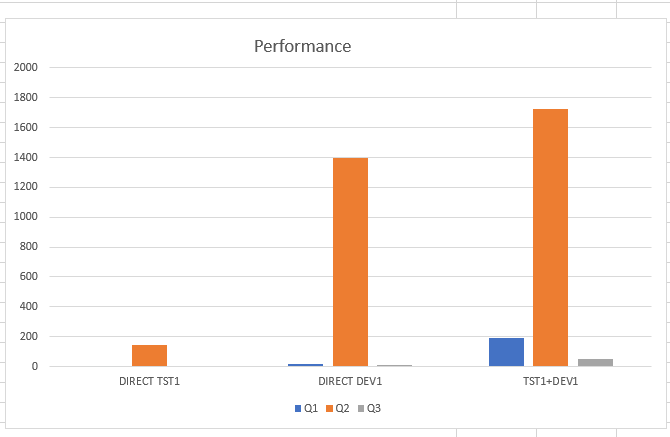
The optimizer of course passes the Where Clause, but still fetches all the necessary data over the network. And that takes time. Note: Runtime in seconds.
Conclusion: Depending on the query, the query performance has an effect. If you only need a few data for a calculation, it is of course not so dramatic, but we achieved a slowness factor between 11 upto 157 in our tests. Since we only tested with simple queries, this is still an important knowhow for us.
SPHINX.AT
YAITCON
Schreibe einen Kommentar