2. Architecture¶
The framework consists of 4 different modules, namely Automation, Core, Security and GDPR.
Each of those will be explained in more detail in the chapters 3 to 6. However, first the data flow, the structure and the loading process will be discussed.
2.1. Data Flow¶
In principle, data is loaded from source systems into an analytical database. The data is loaded largely unchanged and historisation information is added. A few transformations, such as the conversion of date values, can be performed before the data is persisted.
The framework can load data from multiple different sources. A connector is configured for each type of source (e.g. database, files, REST APIs, … - see Figure 1). The loading of the data and the historisation are triggered in near real time, such that the business department is able to make decisions based on live data. Access for reporting by the business department or follow-up systems is secured by a view layer.
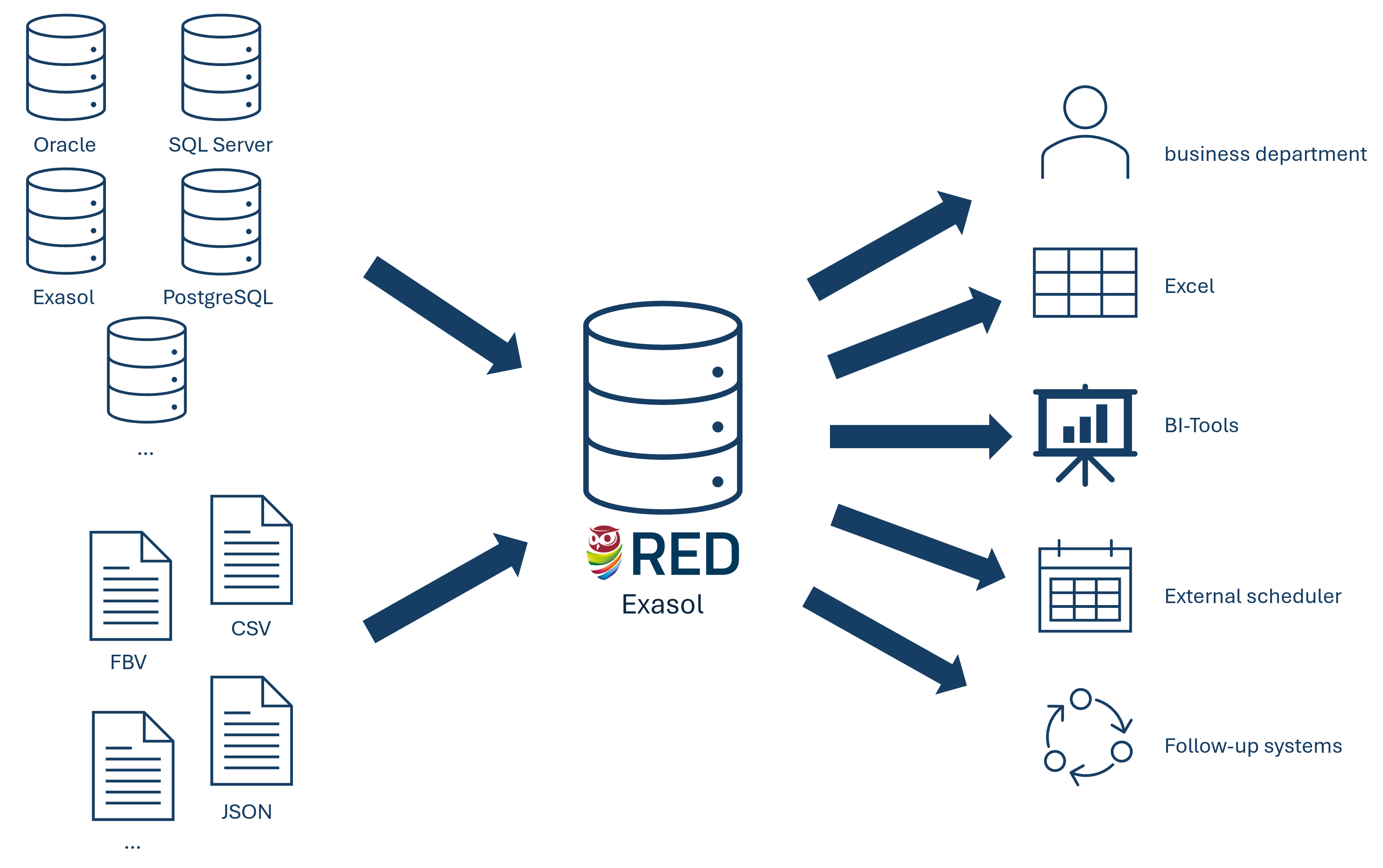
Fig. 2.1 Data sources and consumers in RED¶
2.2. Layered Structure¶
The framework consists of a layered structure (see Figure 2) that is divided into a reporting and a technical layer. The former allows for a secured access by reporting users, the latter is internal and not accessible to users.
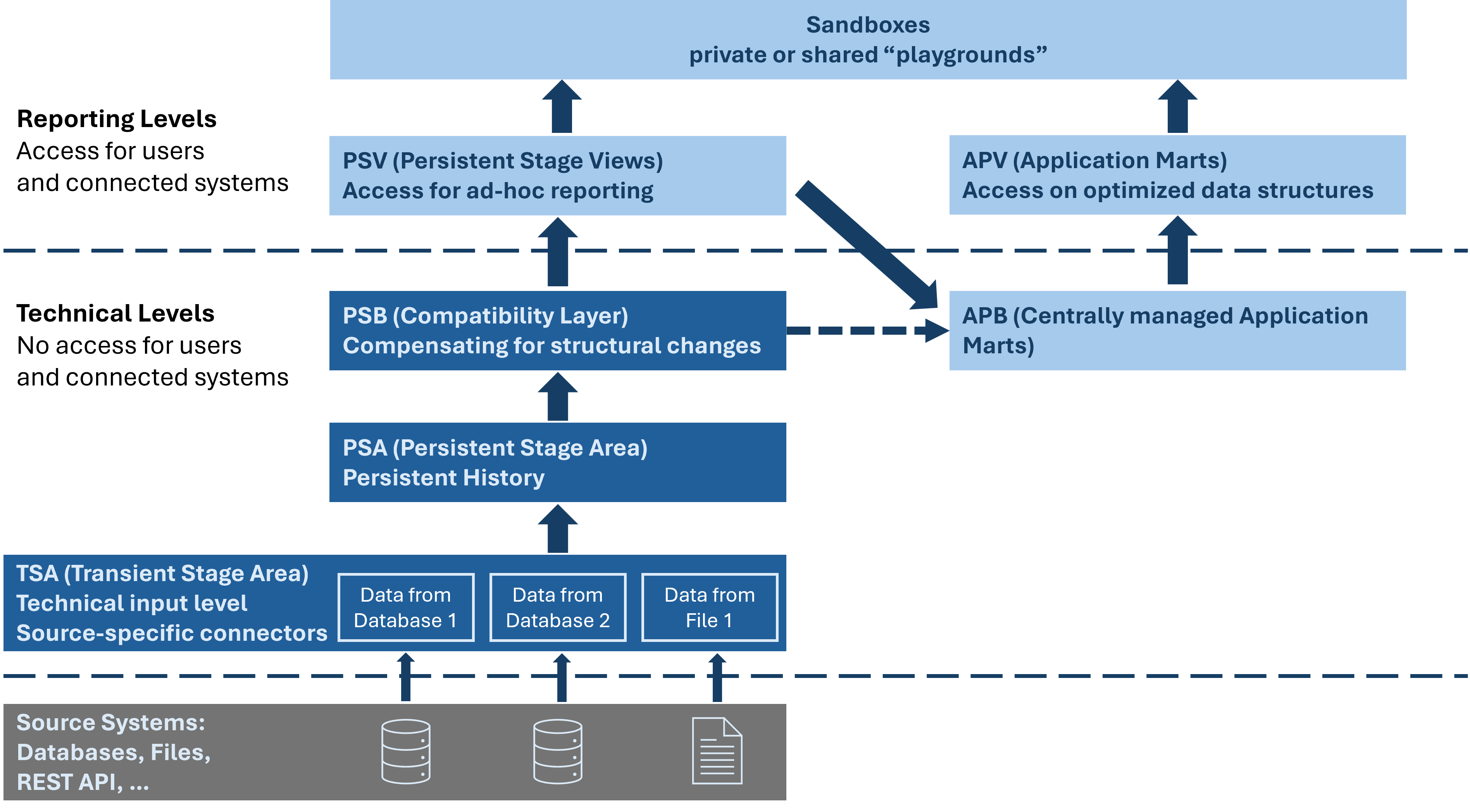
Fig. 2.2 Layered structure¶
2.2.1. Reporting Layer¶
The reporting layer is fully secured and serves as the only way users can get access to data.
2.2.1.1. Persistent Stage Views (PSV)¶
This layer manages access to ad-hoc reporting via automatically generated views. The personalised access rights (row and column level security) are applied in the views of the PSV layer. For that reason, users will only see the data that corresponds to their individual rights. The PSV layer is based on the PSB layer.
2.2.1.2. Application Marts (APV)¶
This layer manages access to centrally managed application marts via automatically generated views. Access rights can be assigned selectively and are independent of the access rights of the PSV layer. The APV layer is based on the APB layer.
2.2.2. Technical layer¶
The technical layer holds the persisted data and is not visible to users.
2.2.2.1. Centrally Managed Application Marts (APB)¶
Centrally managed application marts are schemas that enable the persistence of complex queries and business models (e.g. data modelling as a star schema). They usually consist of views, but the top layer can also be materialised for performance reasons, e.g. for self-service BI tools when a response within milliseconds is necessary. The APB layer is directly based on the views of the PSB layer.
2.2.2.2. Persistent Stage Base (PSB)¶
This layer is a compatibility view layer to compensate for any structural changes in the layers below. Due to this layer a constant PSV layer is presented to the business department no matter what changes appear in the source systems. It consists of DR (dual date range) and TA (technically active) views. DR views show historisation in both time dimensions (business date and technical date), whereas TA views only show technically active data.
The PSB layer is based on the PSA layer. The business attributes of the source tables are displayed 1:1. In addition, renaming or hiding a column and pre-calculations for data enrichment can take place in this layer.
2.2.2.3. Persistent Stage Area (PSA)¶
The PSA is the layer that serves as the data safe. In this layer the target tables with the historicized and persisted data, the technical tables and the views for the loading process are located. Additionally, to the data table, objects with the following postfixes might exist:
Tables:
ERR: Error table for invalid rows
CTL: Control table for historisation process
HT: Hub table for resolved dependencies
Views:
DV: Difference view to detect new, changed and deleted rows
PV: Point-in-time view to set BDATE and TDATE
PV2: Point-in-time view 2 to inherit historisation from the source
HV: Hub view to populate a corresponding hub table
CV: Correction view for missing references in the BSK calculation
CVR: Correction view for missing references in data columns
DEL: Deletion view for history cleanup
FV: Fusion view for mapping inside the BSK calculation
A postfix in this case means <TABLE_NAME>_POSTFIX. In case of time dependencies between two or more tables, the framework automatically ensures that the tables are loaded in the appropriate order.
2.2.2.4. Transient Stage Area (TSA)¶
Every connector loads its data to this temporary stage without any modification. Once the data has been persisted in the PSA, the TSA data will be deleted after an adjustable number of days.
2.3. Loading Process¶
Starting from the source, the data is loaded into the TSA table. The DV view identifies new, changed and deleted rows that are permanently written into the PSA tables. Faulty data records end up in the ERR table. The PV view manages BDATE and TDATE time slices. Other views in the PSA might exist depending on the properties of the source objects.
Database objects whose name begins with “ADM_” contain information for batch control. This level is independent of the data structures loaded and is used to generally manage the system processes (e.g. frequency of execution of jobs or retention periods of log data).